
Linux Latency Cuts: HFT Kernel Bypass Techniques
High-frequency trading (HFT) demands ultra-low latency. Every microsecond matters when processing market data or sending orders. Traditional Linux networking adds delays, but kernel bypass eliminates most of these by allowing direct communication between trading applications and network hardware.
Key Takeaways:
- Why It Matters: Faster processing = better exchange queue positions, higher fill rates, and reduced slippage.
- Top Technologies:
- DPDK: Uses poll mode drivers to process packets in under 80 CPU cycles.
- RDMA: Bypasses both the kernel and TCP/IP stack for ultra-fast server-to-server data transfers.
- Other tools: OpenOnload, TCPDirect, XDP/eBPF.
- Hardware Requirements: High-performance CPUs (AMD EPYC, Intel Xeon), NUMA-aware memory setups, and specialized NICs (e.g., Mellanox, Solarflare).
- Challenges: High CPU usage, setup complexity, and security trade-offs.
Kernel bypass is ideal for HFT systems processing over 1 million packets per second or requiring sub-100 microsecond execution times. Tools like DPDK and RDMA can drastically reduce latency, but they require advanced configurations and specific hardware.
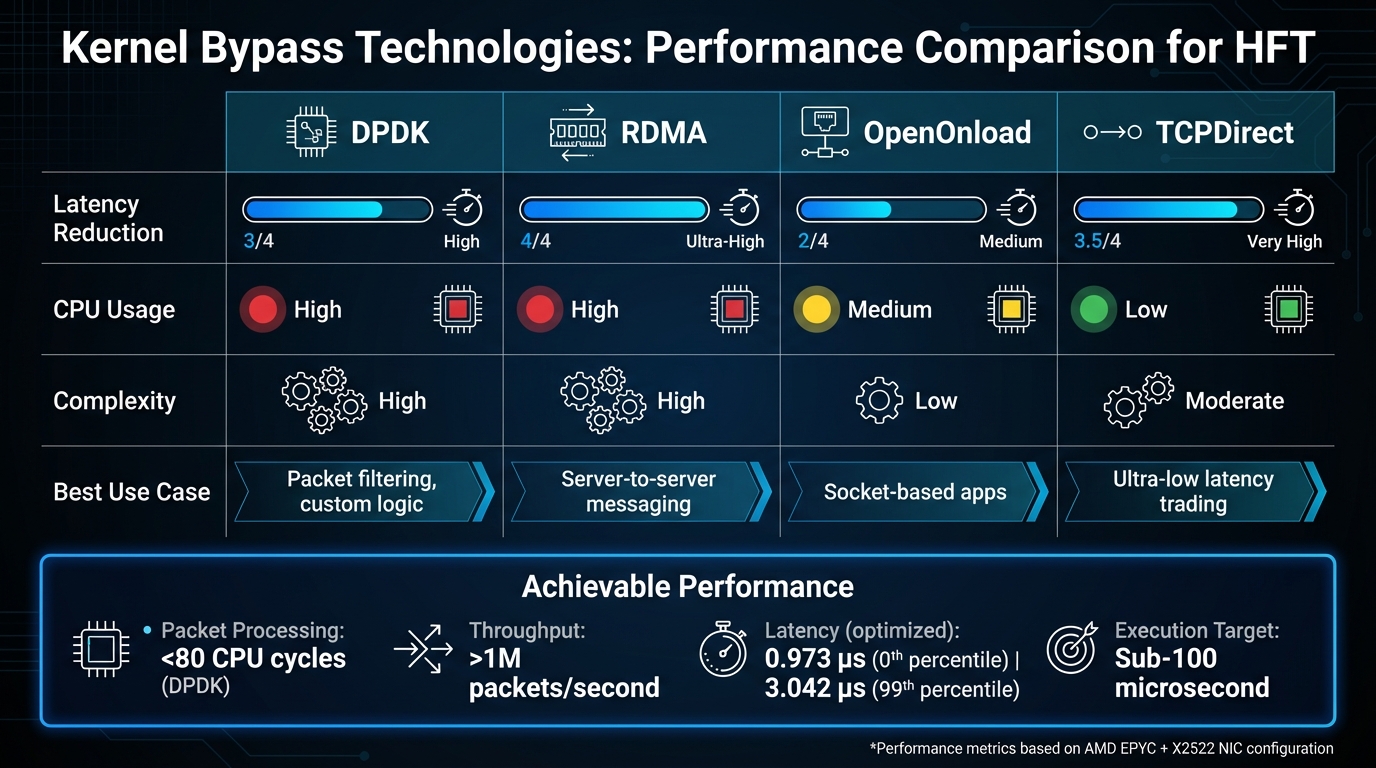
Quick Comparison
| Technology | Latency Reduction | CPU Usage | Complexity | Best Use Case |
|---|---|---|---|---|
| DPDK | High | High | High | Packet filtering, custom logic |
| RDMA | Ultra-High | Low | High | Server-to-server messaging |
| OpenOnload | Medium | Medium | Low | Socket-based apps |
| TCPDirect | Very High | Low | Moderate | Ultra-low latency trading |
For HFT pros, kernel bypass is a game-changer - but only if you're ready to tackle its complexities.
Linux Kernel Bypass Technologies Comparison for HFT Trading
Is Linux Kernel Bypass like NetMap worthwhile for HFT like usage
Latency in Linux-Based HFT Systems
Before diving into optimizing a trading system, it's crucial to pinpoint where delays occur in your infrastructure. In a typical Linux environment, every packet that hits your network interface card (NIC) triggers a chain of events - each adding microseconds to the process. These small delays can quickly add up, creating noticeable performance gaps.
Where Latency Comes From in Linux
When a market data packet reaches the NIC, the hardware generates an interrupt, which temporarily halts the CPU's current tasks. This alone can introduce a delay of about 2–20 µs[6]. From there, the packet moves through the Linux kernel's networking stack, where tasks like IP/TCP/UDP validation, firewall checks, and connection state updates add another 5–50 µs[6].
The next hurdle is crossing the system call boundary. When functions like recv() or read() are called, the CPU has to switch between user mode and kernel mode, creating an overhead of approximately 0.2–5 µs[6]. Then there's memory copying, where data is transferred from the kernel's socket buffer to the application’s memory, consuming both CPU cycles and memory bandwidth[1][6].
If your application isn’t actively polling for packets and instead relies on the kernel to wake it, scheduling delays can tack on an extra 5–100+ µs[6]. During high-traffic periods, such as when over 1 million packets per second are being processed, the standard Linux kernel often struggles to keep pace, leading to dropped packets and missed opportunities[1].
"A trading firm that can process an order book update in 50µs has a massive edge over one that takes 200µs."
- Quant Engineering[6]
Here’s a breakdown of typical latency ranges across different layers:
| Layer | Action | Typical Latency Range |
|---|---|---|
| NIC → DMA → RAM | Hardware decoding and memory transfer | 0.5–5 µs[6] |
| Interrupt Path | CPU state saving and routine execution | 2–20 µs[6] |
| Kernel Stack | Protocol parsing and firewall processing | 5–50 µs[6] |
| Syscall Boundary | User-to-kernel mode switching | 0.2–5 µs[6] |
| Scheduling Delay | Thread sleep/wake cycles | 5–100+ µs[6] |
Understanding these sources of delay is the first step toward accurately measuring and reducing latency.
How to Measure Latency Improvements
Once you’ve identified the primary sources of latency, the next step is to measure both delay and variability. In high-frequency trading, consistent performance often outweighs achieving the lowest possible latency. This is why jitter, or the variation between packet delays, is a critical metric.
Pay special attention to tail latency, particularly the 99th percentile, as it highlights bottlenecks that only surface under heavy load. For example, optimized systems using hardware like AMD EPYC processors paired with X2522 NICs have achieved one-way latencies as low as 0.973 µs at the 0th percentile and 3.042 µs at the 99th percentile[2]. These measurements depend on NICs with hardware timestamping, which minimizes errors introduced by software.
For benchmarking, follow the guidelines in RFC 2544. This methodology outlines specific frame sizes and procedures for evaluating throughput, latency, and frame loss[8]. Tracking zero-loss latency - the round-trip time at a throughput rate where no packets are dropped - can help you identify your system's performance ceiling[8].
Hardware Requirements for Low-Latency Trading
Reducing latency to microsecond levels requires hardware configured for maximum efficiency. Start by ensuring your CPU operates at its peak frequency. Disable power-saving features like C-states and frequency scaling in your BIOS/UEFI settings[8][9]. Processors with strong single-thread performance, such as AMD EPYC or Intel Xeon, are ideal. Additionally, turning off Hyper-threading can improve cache efficiency[9].
A NUMA-aware architecture is equally important. Aligning memory and NICs on the same CPU socket prevents delays caused by cross-socket communication[7][8]. For NICs, consider options designed for kernel bypass, such as DPDK, OpenOnload, or TCPDirect, from vendors like Solarflare (AMD), Mellanox (NVIDIA), or Exablaze[1][3].
Memory configuration also plays a key role. Use huge pages (2MB or 1GB) to reduce TLB misses, disable swap, and lock memory with mlockall() to avoid page faults[9][10]. For a low-latency trading setup, expect hardware costs to range between $5,000 and $15,000[2].
Kernel Bypass Techniques for HFT
Choosing the right kernel bypass technique depends on your hardware, application requirements, and performance goals. Let’s dive into the details of each method.
DPDK (Data Plane Development Kit)
DPDK shifts packet processing to user space using Poll Mode Drivers (PMDs), which continuously poll the NIC for incoming packets. This eliminates the overhead caused by interrupts but comes at the cost of higher CPU usage due to constant polling.
To optimize DPDK, bind your NIC to UIO or, preferably, VFIO drivers. VFIO is often the better choice since it uses IOMMU for improved device isolation and security. Additionally, configure hugepages and core isolation (using isolcpus) to reduce TLB misses and avoid scheduler interference.
DPDK operates on a "run-to-completion" model, where dedicated CPU cores handle packet processing from start to finish without interruption. This makes it an excellent choice for software-defined packet processing or implementing custom protocols on standard hardware.
RDMA (Remote Direct Memory Access)
RDMA takes a different route by offloading networking tasks to specialized hardware known as Host Channel Adapters (HCAs). This allows servers to read or write directly to remote memory, bypassing the CPU, caches, and operating system entirely. The result? Minimal CPU usage and ultra-low latency - often in the single-digit microsecond range for intra-data-center communication [11].
Unlike DPDK, which bypasses the kernel but still relies on a user-space stack, RDMA skips the entire TCP/IP stack. Applications interact with the hardware using the libibverbs library and device files (commonly found at /dev/infiniband/uverbsN) to manage resources like queue pairs and protection domains. While the kernel handles setup tasks like memory registration (control path), all data transfers occur directly in hardware (data path).
RDMA requires memory pinning, which ensures the HCA can access memory pages directly without operating system intervention. To use RDMA effectively, you’ll need compatible HCAs and fabrics, such as Mellanox ConnectX, RoCE, or InfiniBand. Opt for RoCE in Ethernet-based environments or InfiniBand when absolute lowest latency is a priority. RDMA shines in high-performance scenarios like messaging, order routing, and data feeds, where keeping CPU overhead to a minimum is critical.
Other User-Space Networking Options
There are other methods that extend kernel bypass, each with its own trade-offs in terms of integration and API complexity. For example:
-
OpenOnload: This solution intercepts standard BSD socket calls and redirects them through a user-space stack. It’s fully POSIX-compatible, making it easier to integrate with existing applications without requiring major code changes. For even lower latency, its
ef_vicompanion API provides direct Layer 2 access to Ethernet frames, though this may require additional development effort. - TCPDirect: Another offering from Solarflare, TCPDirect delivers ultra-low latency but comes with a more limited feature set. Applications need to adapt to its specific API, which can require moderate integration work.
Additionally, hardware-accelerated solutions like ExaNIC from Exablaze and other SmartNICs offer direct memory access and packet processing capabilities, providing further options for low-latency networking.
| Technology | CPU Impact | Integration Effort | Best For |
|---|---|---|---|
| DPDK | High (constant polling) | High (custom application logic) | High-throughput packet filtering |
| RDMA | Minimal (hardware offload) | High (requires specialized HCAs) | Server-to-server messaging and data feeds |
| OpenOnload | Medium | Low (POSIX compatible) | Accelerating existing socket-based apps |
| TCPDirect | Low | Moderate (custom API) | Ultra-low latency with limited features |
It’s important to note that these high-performance techniques often depend on specific hardware, such as NICs from Mellanox (NVIDIA), Solarflare (AMD), or Exablaze. While this can limit flexibility in infrastructure choices, the performance improvements are often essential for staying competitive in high-frequency trading environments. These tools give traders the edge they need to fine-tune their low-latency systems.
Building a Low-Latency Trading Infrastructure with Kernel Bypass
Linux Configuration for Kernel Bypass
Setting up kernel bypass for reliable performance requires careful system tuning. Start by isolating CPU cores using the isolcpus kernel parameter to dedicate them exclusively to your trading application. This step alone can improve consistency and determinism by about 90% [12], which is critical for achieving the ultra-low latencies needed in high-frequency trading (HFT).
Next, disable the irqbalance daemon. Allowing interrupts to migrate across cores can result in cache misses and latency spikes, so instead, manually bind critical interrupts to specific CPUs. Enabling hugepages (2 MB or 1 GB sizes) is another key optimization - it reduces TLB misses and speeds up memory access. Pair this with numactl to ensure memory is allocated close to the CPU that’s doing the processing, taking advantage of NUMA-aware allocation.
BIOS settings also play a big role in minimizing latency. Disable Intel SpeedStep and C-states to maintain a constant, maximum CPU frequency. Enable the High Precision Event Timer (HPET) for more accurate timing, and set the iommu=pt kernel parameter to improve DMA performance when using drivers like igb_uio or vfio-pci.
For network interfaces, use tools like ethtool to fine-tune NIC settings. On 40 GbE NICs, enable extended tagging and reduce the maximum read request size to 128 bytes to optimize small packet performance. With the right hardware - like an AMD EPYC system paired with an X2522 NIC - these optimizations can bring one-way latencies down to 0.973 microseconds at the 0th percentile and 3.042 microseconds at the 99th percentile [2].
These foundational tweaks ensure your system is optimized for high-speed data handling.
HFT Data Flow in a Kernel-Bypass Setup
In a standard Linux setup, packets travel through multiple layers of the networking stack, adding overhead and limiting throughput to about 1 million packets per second during exchange microbursts [1]. Kernel bypass changes the game by allowing market data to flow directly from the NIC to the user-space buffer, bypassing the kernel entirely. This eliminates context switches, memory copies, and scheduler delays.
Poll Mode Drivers (PMDs) are at the heart of this approach. Instead of relying on interrupts, PMDs continuously check the NIC for new data, enabling a zero-copy data flow. This reduces memory bandwidth usage and significantly boosts performance.
Once this streamlined data flow is in place, integrating kernel bypass into trading platforms becomes much easier.
Using Kernel Bypass with NinjaTrader
By applying the low-latency techniques described above, integrating kernel bypass with NinjaTrader can dramatically improve execution speed. Since NinjaTrader relies on standard sockets, OpenOnload provides a straightforward solution. It intercepts BSD socket calls and redirects them to a user-space stack, requiring no changes to your existing code.
For more advanced setups, consider a hybrid architecture. Deploy a Linux gateway using DPDK or RDMA for high-speed market data and order execution, then forward signals to NinjaTrader through low-latency internal links.
If you’re running NinjaTrader on TraderVPS, SR-IOV (Single Root I/O Virtualization) is essential. This feature partitions a physical NIC into virtual functions that can be assigned directly to your virtual machine, delivering near bare-metal performance. To maximize this setup, configure CPU pinning and ensure BIOS settings like VT-d are enabled.
Kernel Bypass Trade-Offs and When to Use It
Trade-Offs of Kernel Bypass in HFT
Kernel bypass offers ultra-low latency, but it comes with some hefty trade-offs. The most prominent is CPU consumption. With DPDK's polling mode, CPU usage shoots up to 100% on dedicated cores, even when the system is idle. This eliminates interrupt delays but ties up valuable resources [3][5].
Another challenge is complexity. Setting up kernel bypass isn’t straightforward - it requires advanced knowledge of memory management, hardware-level networking, and fine-tuning low-level system settings [3]. Then there’s the issue of hardware dependency, which limits your flexibility. You’ll need specialized hardware to achieve sub-microsecond latencies, making upgrades and infrastructure changes more complicated [2].
Security is another concern. Skipping the kernel’s network stack means bypassing built-in OS-level security checks [3]. You’ll need to create your own safeguards, which adds to the development workload. On top of that, system stability can become a problem if memory management (like hugepages) or hardware-direct buffers aren’t handled properly [3][10].
Considering these trade-offs, it’s vital to weigh the costs and benefits before diving into kernel bypass.
When Kernel Bypass Makes Sense
Kernel bypass is a game-changer when standard Linux networking falls short. If your trading system processes over 1 million packets per second - a common scenario during exchange microbursts - the default kernel stack won’t keep up [1]. Similarly, if you’re aiming for line-rate processing at 10 Gbps or higher without dropping packets, kernel bypass becomes a necessity [1].
This approach is particularly valuable for co-located HFT strategies targeting sub-100 microsecond execution times. In these cases, network latency is often the main bottleneck, and shaving off even a few microseconds can directly impact profitability. With optimized hardware - like an AMD EPYC system paired with an X2522 NIC - you can achieve one-way latencies as low as 0.973 microseconds at the 0th percentile and 3.042 microseconds at the 99th percentile [2].
On the other hand, for strategies like swing trading or lower-frequency algorithmic approaches, kernel bypass isn’t worth the effort. The added complexity and cost won’t yield significant benefits. A step-by-step adoption approach is often the best route. Start with high-level tools like OpenOnload, which maintain POSIX compatibility and work with socket-based applications [1]. After validating the performance improvements, you can explore lower-level APIs like TCPDirect or ef_vi for further fine-tuning [1].
Once you’ve decided that kernel bypass fits your trading needs, having the right infrastructure in place is critical.
Infrastructure Support for Kernel Bypass
TraderVPS offers infrastructure designed to support kernel bypass techniques across various trading setups. The VPS Pro and VPS Ultra plans are ideal for testing kernel bypass implementations like OpenOnload without committing to full hardware ownership. These plans include dedicated CPU cores and high-performance networking, enabling optimizations like hugepages and core isolation.
For more demanding HFT strategies, Dedicated Servers provide the raw performance needed for DPDK and RDMA setups. With direct hardware access, you can fine-tune BIOS settings, bind NICs to user-space drivers like vfio-pci, and fully implement kernel bypass optimizations. These servers also support SR-IOV, allowing you to partition physical NICs into virtual functions that deliver near bare-metal performance in virtualized environments.
TraderVPS infrastructure is built with low-latency trading in mind. Proximity to major exchange data centers and network configurations optimized for minimal jitter ensure that your kernel bypass techniques are supported by a foundation designed to keep latency as low as possible.
Conclusion: Key Takeaways for HFT Professionals
Kernel bypass has transformed how network latency is managed in high-frequency trading (HFT). By cutting out the overhead of the standard Linux stack, tools like DPDK and RDMA can process packets in under 80 CPU cycles while handling over 1 million packets per second without losing any data[1][4]. For co-located HFT strategies aiming for execution times under 100 microseconds, these advancements provide a clear competitive edge.
Choosing between OpenOnload, TCPDirect, DPDK, and RDMA comes down to balancing ease of integration with the need for absolute latency reduction. Applications that rely on sockets can leverage OpenOnload for its POSIX compatibility, making integration faster. However, if you're chasing the lowest possible latency, DPDK and RDMA offer direct hardware access - though they come with increased complexity and require dedicated CPU resources. These tools are the backbone of low-latency trading systems.
"Kernel bypass allows one to achieve lower latencies on software-based trading platforms built on commodity server hardware." - Databento[1]
Hardware optimization is just as critical as software. Achieving ultra-low latencies involves more than simply installing DPDK. You’ll need to implement core isolation using isolcpus, allocate hugepages, fine-tune power management settings at the BIOS level, and ensure your NICs support the required offloads.
To support these advancements, TraderVPS offers infrastructure solutions tailored for kernel bypass. Their VPS Pro, VPS Ultra, and Dedicated Server plans are equipped to handle everything from testing OpenOnload on virtual servers to deploying full DPDK configurations on dedicated hardware with SR-IOV support. With proximity to exchange data centers and network setups designed to minimize jitter, these solutions ensure your kernel bypass strategies hit the performance levels HFT demands.
FAQs
What are the key advantages of using kernel bypass for low-latency trading?
Kernel bypass enables extremely low latency and exceptional throughput by letting trading applications directly interact with the network interface card (NIC) buffers, skipping the kernel’s traditional network stack. This method reduces CPU usage, avoids unnecessary data duplication, and relies on lock-free mechanisms for smooth and efficient data handling.
By steering clear of the kernel, this approach significantly reduces packet loss, even when handling more than 1 million packets per second or operating at speeds beyond 10 Gbps. These advantages make kernel bypass a critical solution for high-frequency trading, where even the smallest time advantage can make a huge difference.
What are the key differences between RDMA and DPDK in terms of latency and CPU usage?
RDMA and DPDK are both kernel-bypass techniques designed to cut down on latency, but they take different approaches when it comes to CPU usage and data transfer.
RDMA (Remote Direct Memory Access) enables data to move directly between the network interface card (NIC) and an application’s memory. By skipping most software layers, it achieves very low CPU usage and highly efficient data transfer. This makes it a perfect fit for environments that demand ultra-low latency.
DPDK (Data Plane Development Kit), in contrast, relies on poll-mode drivers that dedicate a CPU core to continuously pull packets from the NIC. While this method also delivers sub-microsecond latency, it does so at the expense of higher CPU usage, as specific cores are tied up to manage the task.
To put it simply, RDMA excels in CPU efficiency, while DPDK matches its latency performance but requires dedicated CPU resources to do so.
What hardware do I need to effectively implement kernel bypass in HFT systems?
To successfully implement kernel bypass in high-frequency trading (HFT) systems, you'll need a high-performance network interface card (NIC) designed to support userspace drivers or RDMA (Remote Direct Memory Access). NICs from manufacturers like Solarflare, AMD, Mellanox, or Intel are popular choices, as they are often compatible with frameworks like DPDK. This compatibility allows direct access to TX/RX rings from userspace, cutting out the kernel and boosting efficiency.
When selecting a NIC, prioritize features like zero-copy I/O, lock-free buffers, and the ability to handle line-rate processing at 10 Gbps or higher. These capabilities ensure the NIC can process millions of packets per second without requiring kernel intervention. For those seeking even lower latency, RDMA-capable NICs, such as the Mellanox ConnectX series, take performance a step further by bypassing both the kernel and the TCP/IP stack, making remote memory transfers lightning-fast.
To complete the setup, allocate dedicated CPU cores for poll-mode processing. This ensures the system is finely tuned for the ultra-low-latency demands of high-frequency trading environments.










